ChatGPTなどのAIクローラーのWebサイトへのアクセスを拒否する
OpenAIが提供しているChatGPTをはじめ多くのAIクローラーは、インターネット上の膨大な情報を収集して、学習をしながら情報を処理していますので、Webサイトの情報もAIの学習に使われています。
Webサイトに掲載している情報の中では、重要な情報なためAIツールで使われたくないといったこともあります。
また、会員制のクローズドサイトの情報も収集できるのではないかという噂もあるので、こうした情報も収集されたくない場合は、クローラーのアクセスを拒否しておく必要があります。
ということで今回は、ChatGPTなどのAIクローラーのWebサイトへのアクセスを拒否する方法についてご紹介していきます。
自社サイトや個人サイト、ブログなどの情報を収集されたくない場合は、robots.txtを利用してアクセスを制御を行います。
robots.txtとは、検索エンジンのクローラーに対して、サイトのクロールを制御するためのファイルになります。
ChatGPTのクローラーをブロック
robots.txtでは、User-agent / Disallow / Allow(他、Sitemapなど)といった記述で制御を行います。
「User-agent」には、クロールを制御(拒否)するクローラーを指定します。
「Disallow」はクロールの制御(拒否)となります。対象のディレクトリなどを指定します。
ChatGPTのクローラーをサイト全体、すべてのページのアクセスを拒否する場合は、以下のようにrobots.txtに記述します。
User-agent: ChatGPT-User
Disallow: /
User-agentは「ChatGPT-User」として、改行して2行目にDisallowをルートディレクトリ「/」と指定します。
robots.txtを初めて触れるという方は、「robots.txtってどうやって用意するの?」となるかと思いますが、PCに入っているテキストエディタで簡単に作成できます。(デフォルトで搭載されているメモ帳でも)
注意点としては、テキストファイルの文字コードは「UTF-8」とする必要があります。
robots.txtが作成できましたら、Webサイトのルートディレクトリにアップロードします。
以下の例は、FTPクライアントソフトを使った例です。
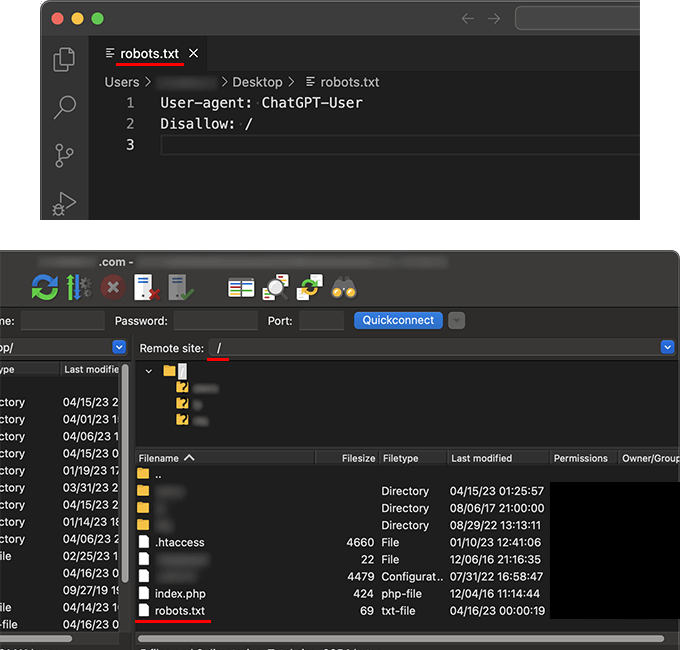
ファイルのアップロードは、レンタルサーバのファイルマネージャーからも行えます。
特定のディレクトリやファイルにアクセスさせたくない場合は、Disallowに対象のディレクトリを指定して、指定したディレクトリ配下のページへのアクセスを拒否します。
User-agent: ChatGPT-User
Disallow: /not-crawl-directory/
メンバーシップなどの会員制や、有料コンテンツとして提供しているページなどでは、対象のページがあるディレクトリごとクロールを拒否させる必要はあるでしょう。
また、サイト自体はクロールを拒否するけど、一部のディレクトリやページは許可させることもできます。
「Allow」はクロールの許可となります。
先に記述しているDisallowで指定しているディレクトリ配下のサブディレクトリや、特定ページへのクロールを許可します。
User-agent: ChatGPT-User
Disallow: /
Allow: /directory-1/
Allow: /directory-2/
Allow: /directory-3/no-block.html
サイト全体ではクロールを拒否させておきたいが、会社や事業に関するページの情報は、世の中に周知してもらうためにオープンにしておきたいといった場合に、部分的にクロールを許可させたりできます。
ちなみに、「Disallow: 」のようにDisallowに何も記述しなかったり記述自体がない場合は、すべてのページのアクセス許可となりますので、Disallowの記述は忘れないようにしてください。
ChatGPTのクローラーのブロックについては、OpenAIのドキュメントでも確認できます。
OpenAI (ChatGPT-User)
https://platform.openai.com/docs/plugins/bot
Common Crawlのクローラーをブロック
Common Crawl(コモン・クロール)は、インターネット上のWebサイトをクロールしてデータを収集し、アーカイブを提供している非営利組織になります。
ChatGPTも独自のデータ収集の中でCommon Crawlのデータを利用しているので、クロールを拒否する場合はCommon Crawlも一緒に設定しておく必要があるでしょう。
User-agent: CCBot
Disallow: /
Common Crawlのクローラーのブロックについては、以下のFAQページにて掲載されております。
Frequently Asked Questions (How can I block this bot?)
https://commoncrawl.org/big-picture/frequently-asked-questions/
ディレクトリやページに対する制御も、先ほどと同じように指定していきます。
特定のディレクトリをブロック
User-agent: CCBot
Disallow: /not-crawl-directory/
サイト全体ではブロックして、特定のディレクトリやページは許可する
User-agent: CCBot
Disallow: /
Allow: /directory-1/
Allow: /directory-2/
Allow: /directory-3/no-block.html
今後もAIのいろんなサービスが登場してくると思いますが、それに合わせて必要に応じてアクセスを拒否させる必要はありそうですね。
ちなみにAI関連意外にも、User-agentは以下のページでご確認することもできます。
User Agents
https://user-agents.net/bots
Botのほか、BrowserやDeviceなどもありますので、いろいろとWebで活用できるかと思います。