Processingでいろんな英語フォントや日本語フォントデータの作成する

Processingでデジタルアートを創作するにあたり、文字やワードをデザインに取り込む中でフォントの種類にこだわりを持つことは多いでしょう。
いろんなフォントを一つのスケッチで複数扱うことでデザインの幅がまた一層広がります。
Processingでフォントを取り扱う時に意外とつまづきそうなのは日本語対応のフォントデータの作成でしょうか。
そこで、ここではいろんな英語フォントや日本語に対応したフォントを利用するために、フォントデータを作成する方法をご紹介します。
フォントデータの作成
Processingで利用できるフォントデータはvlw形式となります。
システムに入っているフォントをもとに、利用したいフォントをフォントデータへと変換していきます。
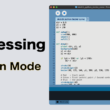
Processingのメニューの「ツール」から「フォント作成」を選択します。
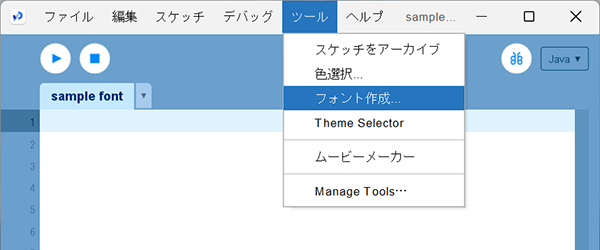
フォント作成画面で作成したいフォントを選択して設定を行っていきます。
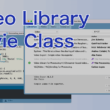
システムに入っているフォントがリストで表示されますので、フォントリストの中からデータを作成したフォントを選びます。
サイズはデフォルトの48で良いでしょう。もしデザインの中でフォントサイズを48以上にするのであれば大きくしてもらっても構いません。ただファイルの容量が大きくなるため重くなり、プログラムを実行する時にフォントの表示が遅くなる恐れがあります。
アンチエイリアスを有効にすると思うので、スムーズのチェックボックスにはチェックを入れておきます。
ファイル名はデフォルトでフォント名とサイズとなります。ファイル名は自由に変更してもらってもいいですが、わかりやすいのでそのままでもいいでしょう。
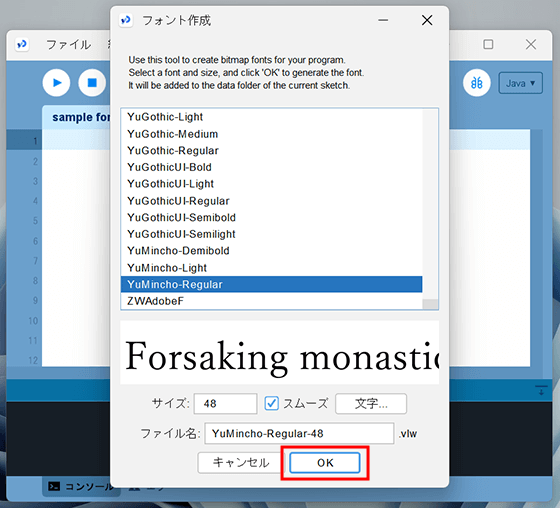
最後に「OK」を選択してフォントデータの作成となります。
作成したvlw形式のフォントデータはプロジェクトファイルのdataフォルダに格納されます。
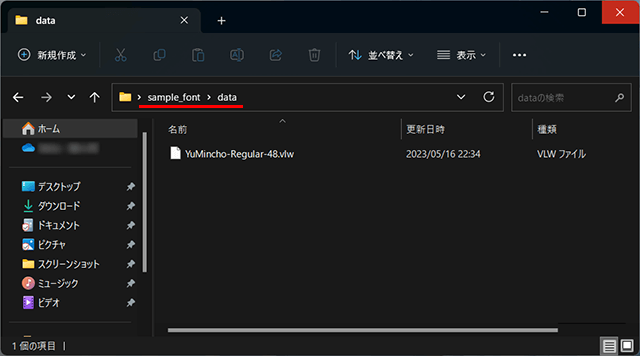
英語フォントの場合は上記の方法で問題ないでしょう。
しかし、日本語フォントデータを作成する場合は文字設定など、少し細かな設定が必要になります。
日本語フォントデータの作成
これから日本語に対応したフォントを作成していくわけですが、日本語に対応していないフォントに対して日本語を使えるように変換して出力しようとしてもエラーを起こします。とくにオシャレな英語フォントを利用するだけでしたらそこまで手が掛からないですが。
日本語に対応したフォントを選んでProcessingで利用できるように変換していきましょう。
例として、MS-PMinchoのフォントデータを作成してみます。
フォントリストから「MS-PMincho」を選択します。
英語フォントの利用だけでしたら文字の設定は必要ないですが、日本語に対応したフォントで日本語に対応する場合は文字の設定が必要になります。
「文字」のボタンを選択してフォントの設定に入ります。
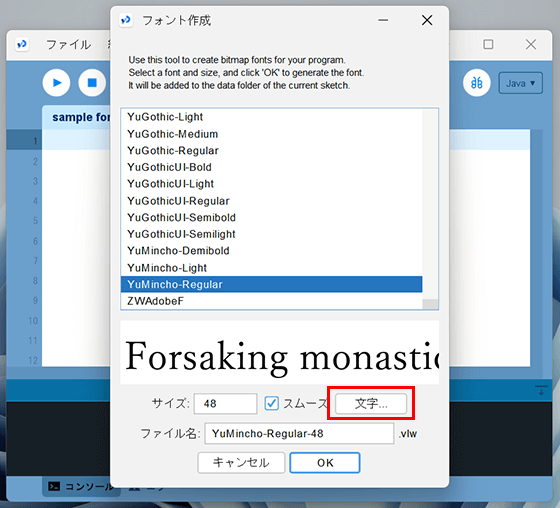
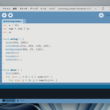
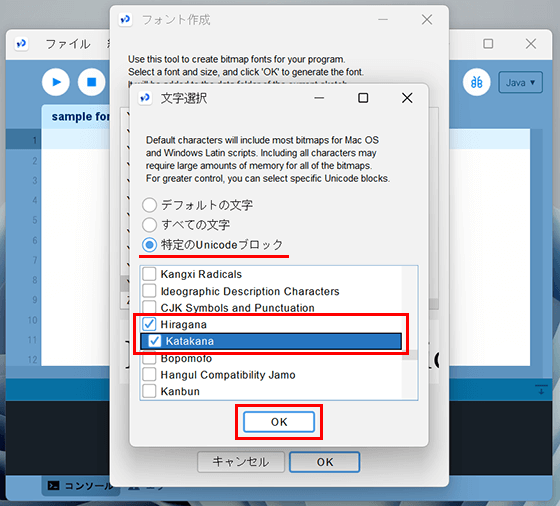
文字選択の項目で「Specific Unicode Block」のラジオボタンを選択します。
下のリストの中から「Hiragana」や「Katakana」「CJK Unified Ideographs」などの項⽬にチェックを⼊れます。
ひらがなとカタカナと現代の中国と日本で多く利用されている字体を利用できるようにします。
その他、必要に応じて文字の種類を選択します。
主に以下の項目が、日本語に対応するために必要になります。
Basic Latin
半⾓英数
CJK Symbols and Punctuation
句読点、全⾓括弧
Hiragana
ひらがな
Katakana
カタカナ
CJK Unified Ideographs
統合漢字
Halfwidth and Fullwidth Forms
全⾓英数、全⾓記号、半⾓カナ
もし、半角英数字や日本語のひらがな、カタカナには対応しているが、漢字には対応していないフォントを作成する場合には、「CJK Unified Ideographs」にチェックを入れるとエラーとなります。
設定が完了したら最後に「OK」ボタンを選択、フォント作成画面でも「OK」ボタンを選択してフォントデータの作成となります。
プロジェクトフォルダのdataフォルダに作成したvlw形式のフォントデータが格納されます。
あとはフォントを格納するPFont変数を作成して、loadFont()でフォントを読み込んでtextFont()でフォントの使用を設定。
draw関数内でtext関数を使って日本語のテキストを表示します。
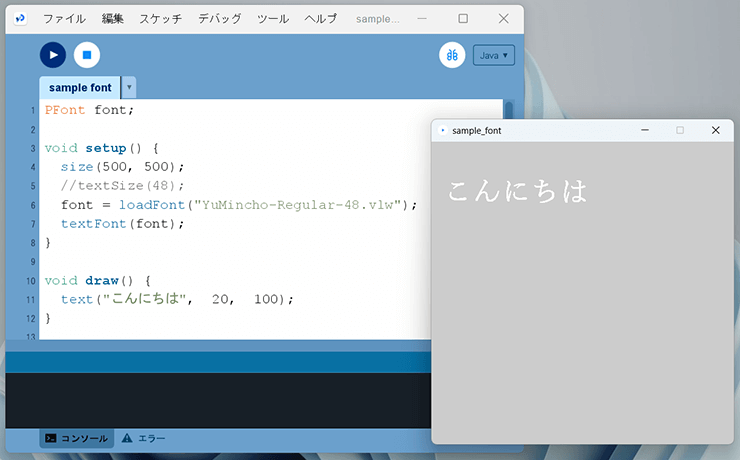
無事、作成したフォントで日本語も問題なく表示されます。
これでひらがなやカタカナ、そして多くの漢字が利用できます。